展望2024:Exploratory Data Analysis: The Ultimate Workflow (with Python)
Published by 劉正山,



You have 2 free member-only stories left this month.

Exploratory Data Analysis: The Ultimate Workflow
Explore the true potential of your data with Python
Are you tired of starting from scratch every time you need to explore your data, without a clear roadmap? Look no further!
I will guide you through a step-by-step process using Python to uncover valuable insights and trends hidden in your data. Whether you’re a beginner or an experienced data analyst, this article has something for you.
We will look at different ways in which you can explore your dataset, depending on your end goal, with clear steps and objectives for each of them.
Disclaimer: we will focus on tabular data only, so if you need a similar process for images, text, etc. this article is not for you. I might do a similar one for those types of data in the future, let me know in the comments if this would interest you.
Introduction
The first thing we need to have in mind when exploring data is why we are doing it. There are multiple reasons to explore a dataset, the main ones usually being:
- understanding your data before building an ML model
- analysis to uncover interesting patterns
- sheer curiosity
Depending on your goal, the analysis can take slightly different forms, but the basic structure I use is this:
- Loading libraries and data
- Reading data documentation
- Univariate data analysis
- Bivariate data analysis
- Multivariate data analysis
- Insights and next steps
If your goal is to build an ML model in the end, you will dedicate more time exploring the target variable. If your goal is pure curiosity, on the other hand, your approach can be much less structured.
Let us now go through each of those steps in detail, working on a real dataset. Our goal will be to find interesting patterns regarding relationships between variables and how customers differ from each other. These insights can then be used for ML tasks such as clustering and customer scoring.
Loading libraries and data
First thing we need to do is import the necessary Python libraries:
import numpy as np
import pandas as pd
import matplotlib.pyplot as pltpandas is the main library for dealing with tabular data, and it allows us to filter, group, join our data, and much more.
matplotlib will be used to create data visualizations.
Then, we load the data using pandas, and take our first look at it:
df = pd.read('marketing_campaign.csv', sep='t')
print(data.shape)
data.head()
We can already have an idea of the data dimensions (2240 rows and 29 columns) as well as some of the available columns.
Reading data documentation
It is important to understand the meaning behind each column and how they were built. Although we can usually infer the meanings from their names, this is not always the case. Ideally, you have some access to the data’s documentation or to the entity who built the dataset.
Here’s the list of variables and their meaning, taken from the data source:
# People
ID: Customer's unique identifier
Year_Birth: Customer's birth year
Education: Customer's education level
Marital_Status: Customer's marital status
Income: Customer's yearly household income
Kidhome: Number of children in customer's household
Teenhome: Number of teenagers in customer's household
Dt_Customer: Date of customer's enrollment with the company
Recency: Number of days since customer's last purchase
Complain: 1 if the customer complained in the last 2 years, 0 otherwise
# Products
MntWines: Amount spent on wine in last 2 years
MntFruits: Amount spent on fruits in last 2 years
MntMeatProducts: Amount spent on meat in last 2 years
MntFishProducts: Amount spent on fish in last 2 years
MntSweetProducts: Amount spent on sweets in last 2 years
MntGoldProds: Amount spent on gold in last 2 years
# Promotion
NumDealsPurchases: Number of purchases made with a discount
AcceptedCmp1: 1 if customer accepted the offer in the 1st campaign, 0 otherwise
AcceptedCmp2: 1 if customer accepted the offer in the 2nd campaign, 0 otherwise
AcceptedCmp3: 1 if customer accepted the offer in the 3rd campaign, 0 otherwise
AcceptedCmp4: 1 if customer accepted the offer in the 4th campaign, 0 otherwise
AcceptedCmp5: 1 if customer accepted the offer in the 5th campaign, 0 otherwise
Response: 1 if customer accepted the offer in the last campaign, 0 otherwise
# Place
NumWebPurchases: Number of purchases made through the company’s website
NumCatalogPurchases: Number of purchases made using a catalogue
NumStorePurchases: Number of purchases made directly in stores
NumWebVisitsMonth: Number of visits to company’s website in the last monthIn the data, we can see that there are two variables that are not in that list: Z_CostContact and Z_Revenue, which are always equal to 3 and 11, respectively. I assume they mean the cost of contacting a customer and the associated revenue if a customer accepts the offer, although we can’t be 100% sure. Either way, since they are constants, they are not relevant for our analysis. They could be relevant if we had a classification task in hand, and wanted to calculate a cost function based on false positives and false negatives.
Univariate data analysis
Univariate analysis means looking at each variable individually, including its distribution, if any values are missing, outliers and so on. This helps better understand each of them individually, and also plan how to address potential issues with the data.
Data types
With the dtypes attribute, we can easily access the types of each variable to see if they match what we saw in the documentation:
ID int64
Year_Birth int64
Education object
Marital_Status object
Income float64
Kidhome int64
Teenhome int64
Dt_Customer object
Recency int64
MntWines int64
MntFruits int64
MntMeatProducts int64
MntFishProducts int64
MntSweetProducts int64
MntGoldProds int64
NumDealsPurchases int64
NumWebPurchases int64
NumCatalogPurchases int64
NumStorePurchases int64
NumWebVisitsMonth int64
AcceptedCmp3 int64
AcceptedCmp4 int64
AcceptedCmp5 int64
AcceptedCmp1 int64
AcceptedCmp2 int64
Complain int64
Z_CostContact int64
Z_Revenue int64
Response int64
dtype: objectThey all seem more or less coherent with what we would expect, except for a few cases:
- Education and Marital_Status could be categories instead of objects
- Dt_Customer should be a date and not an object
- If we wanted to save memory space, Income could also be converted to int64 instead of float.
Since this is only an exploration, and we are not cleaning data yet, the only change we will make for now is to convert Dt_Customer to date, to allow for some specific date analysis later on.
Duplicate values
In our case, a duplicate value means having the same value for the ID column: data.duplicated(subset=['ID']).sum() yields 0, meaning there are no duplicates.
Missing values
Checking for missing values is paramount before we go any further:
# Missing values
data.isna().sum()ID 0
Year_Birth 0
Education 0
Marital_Status 0
Income 24
Kidhome 0
Teenhome 0
Dt_Customer 0
Recency 0
MntWines 0
MntFruits 0
MntMeatProducts 0
MntFishProducts 0
MntSweetProducts 0
MntGoldProds 0
NumDealsPurchases 0
NumWebPurchases 0
NumCatalogPurchases 0
NumStorePurchases 0
NumWebVisitsMonth 0
AcceptedCmp3 0
AcceptedCmp4 0
AcceptedCmp5 0
AcceptedCmp1 0
AcceptedCmp2 0
Complain 0
Z_CostContact 0
Z_Revenue 0
Response 0Our data looks pretty clean, except for Income, for which there are 24 missing values (around 1%). We can move on with the data as it is, but we note these missing values, that could be addressed by imputation later on.
Distributions
For all the numeric and date variables, we can look at their distributions by using different plots. The most common ones are histograms, boxplots, violin plots, kernel density estimations and empirical cumulative distributions. Even though they all serve slightly different purposes, you don’t need all of them.
Different people have different preferences depending on the use case. Rule of thumb: when looking at variables for the whole sample, go for histograms, boxplots or kernel density estimations. When comparing distributions between groups, boxplots, violin plots and empirical cumulative distributions work better.
Here, we are still focusing on each variable individually, so I’ll go for boxplots:
continuous_vars = [
'Year_Birth', 'Income', 'Kidhome', 'Teenhome',
'Recency', 'MntWines', 'MntFruits', 'MntMeatProducts',
'MntFishProducts', 'MntSweetProducts', 'MntGoldProds',
'NumDealsPurchases', 'NumWebPurchases', 'NumCatalogPurchases',
'NumStorePurchases', 'NumWebVisitsMonth'
]
fig, axes = plt.subplots(4,4) # create figure and axes
for i, el in enumerate(list(data[continuous_vars].columns.values)):
a = data.boxplot(el, ax=axes.flatten()[i], fontsize='large')
fig.set_size_inches(18.5, 14)
plt.tight_layout()
plt.show()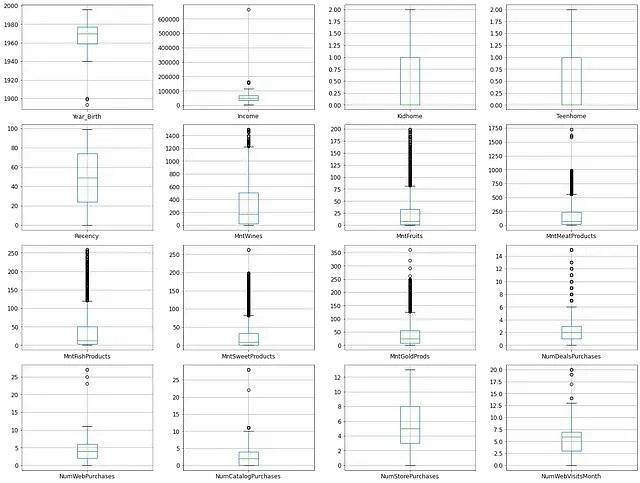
Take the time to look at each boxplot individually, and think of what conclusions do you get from each one. Here are mine:
- Year_Birth: most values between 1960 and 1980, looks reasonable. Some of them are around 1900 or even less, which looks weird.
- Income: data seems skewed by one big value that is above 600k. All the others are 0 and 100k. What should we do with this outlier?
- KidHome and Teenhome: both variables behave normally, ranging between 0 and 2.
- Recency: symmetrical distribution, ranging between 0 and 100, with no outliers.
- MntWines, MntFruits, MntMeatProducts, MntFishProducts, MntSweetProducts, MntGoldProds all behave similarly, skewed to the right, although in different scales. It could be interesting to create new variables based on the percentage of the customer’s total spending per category.
- NumDealPurchases, NumWebPurchases, NumCatalogPurchases also show similar behaviors, skewed to he right and no outliers.
- NumStorePurchases has a more symmetrical distribution. It could also be interesting to create new variables based on the percentage of the customer’s total purchases per channel
- NumWebVisitsMonth is also right-skewed with no outliers
Categories
Now, one easy way of looking at categorical variables is by using barplots:
# Categories
categorical_vars = [
'Education', 'Marital_Status', 'AcceptedCmp1',
'AcceptedCmp2','AcceptedCmp3', 'AcceptedCmp4',
'AcceptedCmp5', 'Complain', 'Response'
]
fig, axes = plt.subplots(3,3) # create figure and axes
for i, el in enumerate(data[categorical_vars]):
counts = data[el].value_counts()
counts.plot(
kind="barh",
ax=axes.flatten()[i],
fontsize='large',
color=color
).set_title(el)
fig.set_size_inches(15, 7)
plt.tight_layout()
plt.show()
My conclusions:
- Education: we have many people with PhDs in our sample, which does not seem to fit what we see in real life. This might mean that our sample is biased or that people lied in the survey.
- Marital_Status: Apart from the usual statuses, we see some weird ones like "YOLO" and "Absurd", which indicate some people did not take the question seriously. What can we do with these values?
- AcceptedCmp1, AcceptedCmp2, AcceptedCmp3, AcceptedCmp4 and AcceptedCmp5: values are unbalanced, with many more 0s than 1s. AcceptedCmp2 also seems suspiciously more unbalanced than the others.
- Complain: highly unbalanced and, as we can see with
data.Complain.describe(), only 0.9% of customers seem to have complained. Is this variable useful? - Response: not highly unbalanced.
Looking at the Response variable, I wonder if it corresponds to having at least one of AcceptedCmp variables equal to 1? It turns out that this is not the case
data[
['AcceptedCmp1','AcceptedCmp2','AcceptedCmp3','AcceptedCmp4','AcceptedCmp5']
].max(axis=1)==data['Response']0 False
1 True
2 True
3 True
4 True
...
2235 True
2236 False
2237 False
2238 True
2239 False
Length: 2240, dtype: boolDates
Finally, we look at our only date variable with data.Dt_Customer.describe(datetime_is_numeric=True) :
count 2240
mean 2013-07-11 22:57:38.571428608
min 2012-01-08 00:00:00
25% 2013-01-19 18:00:00
50% 2013-07-11 00:00:00
75% 2013-12-30 06:00:00
max 2014-12-06 00:00:00
Name: Dt_Customer, dtype: objectWe see that dates frange from 1/8/2012 to 6/12/2014. We can also use a line chart with the number of customers per month to have a better view, with:
data.groupby(
pd.Grouper(key='Dt_Customer', freq='M')
).count().ID.plot(x='index', color=color)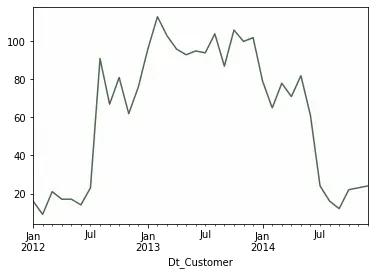
Most customers in the database seem to have been registered between July 2012 and July 2014. What happened in the 6 months before and after that, where we have some customers, but not many?
Bivariate data analysis
So far we have looked at each variable individually, but it is also important to look at the relationships between them, starting with bivariate analysis.
Relationships
The most common way of doing this is for numerical variables is by using scatter plots. Fortunately, pandas has a builtin function that does that for all pairs of variables automatically, called scatter_matrix:
sm = pd.plotting.scatter_matrix(
data[continuous_vars],
color=color, figsize=(12, 12), alpha=0.2
)
# hiding ticks
for subaxis in sm:
for ax in subaxis:
ax.xaxis.set_ticks([])
ax.yaxis.set_ticks([])
ax.xaxis.label.set_rotation(45)
ax.yaxis.label.set_rotation(0)
ax.yaxis.label.set_ha('right')
# hiding one half of the matrix + the diagonal
for i in range(np.shape(sm)[0]):
for j in range(np.shape(sm)[1]):
if i <= j:
sm[i,j].set_visible(False)
pic = sm[0][0].get_figure()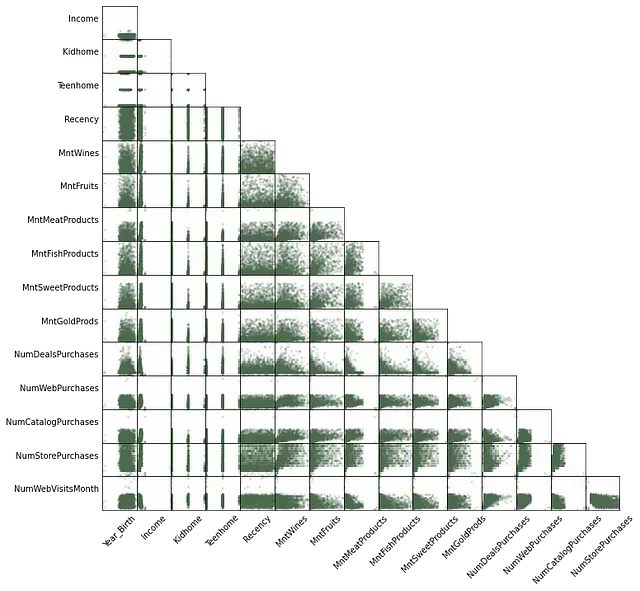
With this kind of big plot, we have a tendency to overlook the individual details, so let us try to spot interesting patterns:
- it is hard to spot any relationships with Income and Year_Birth because the outliers make their plots look compressed
- same for NumWebPurchases and NumWebVisitsMonth, even though we had not spotted those outliers from the boxplot (they didn’t seem that discrepant to me)
- it is also hard to spot relationships between Kidhome and Teenhome because they are not really continuous (despite what the Census says, no one has 1.8 kids)
- NumDealsPurchases and NumCatalogPurchases seem to have a negative correlation with the Mnt… variables
- NumWebPurchases seems to have a positive non-linear correlation with the Mnt… variables
- NumWebPurchases and NumWebVisitsMonth do not seem as highly correlated as I expected
- most Mnt… variables seem to have positive correlations with each other
Given these first impressions, it’s worth it checking a few of these relationships in more detail after getting rid of outliers. There are many ways of doing that, and we could look at each variable individually to define what is an outlier. We will take an easier approach, however, since the goal is to have an overview:
# Getting rid of outliers
from scipy import stats
data_subset = data[continuous_vars].dropna()
data_subset = data_subset[(np.abs(stats.zscore(data_subset)) < 2).all(axis=1)]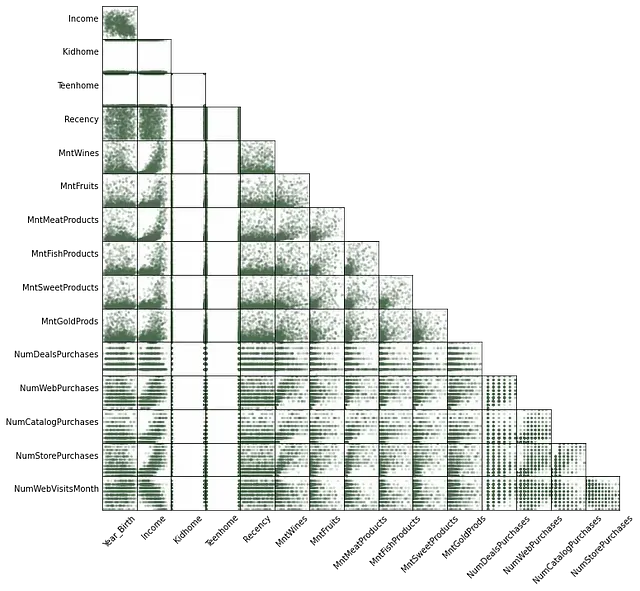
Now we can see that:
- Income seems strongly correlated with most variables, while Year_Birth does not
- Specifically, Income is negatively correlated with NumWebVisitsMonth
- The correlation between Income and the Mnt… variables is mostly positive and non-linear
We have looked at the continuous variables, let us now look at the relationships between the date variable and the rest.
For dates, the most common visualization is a line plot. Since variables have very different scales, it is hard to visualize all of them in the same plot.
Instead, we can visualize different plots for different subsets of those variables:
data_subset = data[['Dt_Customer','Kidhome','Teenhome']]
data_subset.groupby(
pd.Grouper(key='Dt_Customer', freq='M')
).mean().plot()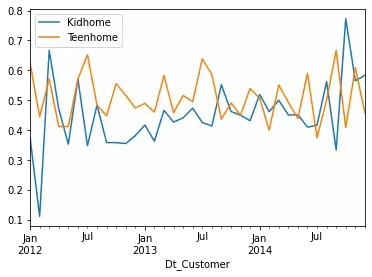
Kidhome and Teenhome seem stable throughout time. The extreme values at the beginning and end of series are probably due to the low numbers of total observations at those moments. Those two variables seem to behave very similarly, so I wonder if it’s not worth it adding them into one?
Next, Income:
data_subset = data[['Dt_Customer','Income']]
data_subset.groupby(
pd.Grouper(key='Dt_Customer', freq='M')
).mean().plot()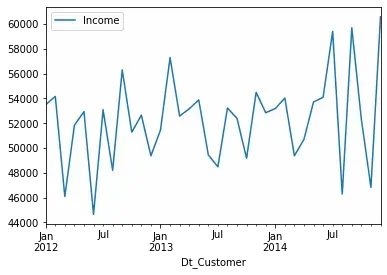
Average income seems to be getting higher with time, but that trend is not super clear.
data_subset = data[['Dt_Customer','MntWines', 'MntFruits', 'MntMeatProducts',
'MntFishProducts', 'MntSweetProducts', 'MntGoldProds']]
data_subset.groupby(
pd.Grouper(key='Dt_Customer', freq='M')
).mean().plot()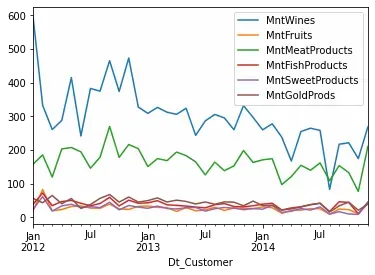
Overall sales of most products seem to be decreasing over time. That trend is confirmed when we look at the number of purchases:
data_subset = data[['Dt_Customer','NumDealsPurchases', 'NumWebPurchases', 'NumCatalogPurchases',
'NumStorePurchases', 'NumWebVisitsMonth']]
data_subset.groupby(
pd.Grouper(key='Dt_Customer', freq='M')
).mean().plot()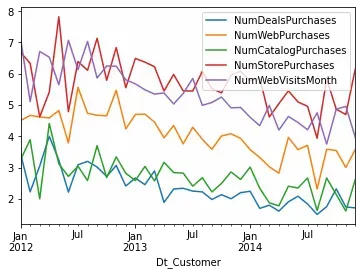
Next, let us look at the variables related to campaign response and complaints:
data_subset = data[['Dt_Customer', 'AcceptedCmp1',
'AcceptedCmp2','AcceptedCmp3', 'AcceptedCmp4',
'AcceptedCmp5', 'Complain', 'Response']]
data_subset.groupby(
pd.Grouper(key='Dt_Customer', freq='M')
).mean().plot()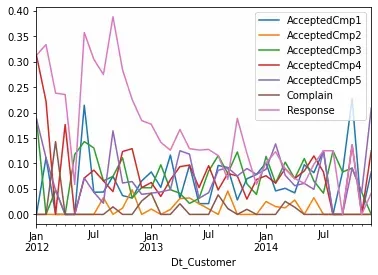
Hard to see much there, right? Let’s merge all of the AcceptedCmp… variables to see if it get’s clearer:
data_subset = data[['Dt_Customer', 'AcceptedCmp1',
'AcceptedCmp2','AcceptedCmp3', 'AcceptedCmp4',
'AcceptedCmp5', 'Complain', 'Response']]
data_subset['AcceptedAnyCmp'] = data[
['AcceptedCmp1','AcceptedCmp2','AcceptedCmp3','AcceptedCmp4','AcceptedCmp5']
].max(axis=1)
data_subset.drop(['AcceptedCmp1','AcceptedCmp2','AcceptedCmp3','AcceptedCmp4','AcceptedCmp5'], axis=1, inplace=True)
data_subset.groupby(
pd.Grouper(key='Dt_Customer', freq='M')
).mean().plot()
Not only my initial hypothesis that Response and AcceptedAnyCmp were the same thing was wrong, they seem to follow opposite trends.
Finally, let us check the relationship between some categorical variables. We could use plots for that, but I think tables will do the job:
pd.crosstab(
index=data['Marital_Status'], columns=data['Education'],
normalize='columns'
).round(2)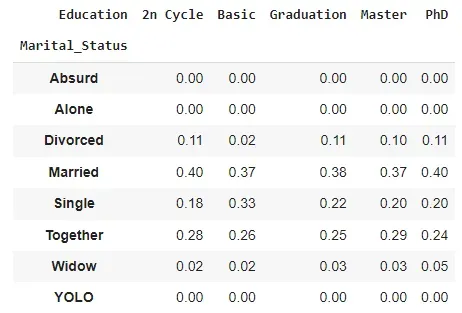
This is how we can interpret those numbers: 40% of people who have a PhD are also married (in our sample, of course).
If the numbers are roughly the same in each column, it means we can’t infer much about Education from Marital_Status (or vice-versa). It seems to be the case here, except for the "Basic" education, for which people seem to be less likely to be divorced and more likely to be single. This is probably due to their age.
pd.crosstab(
index=data['Marital_Status'], columns=data['Response'],
normalize='columns'
).round(2)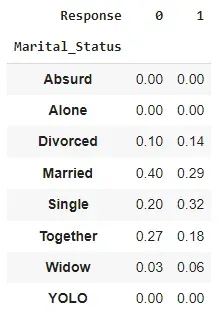
This tab is more interesting: we can see that people who are not in a relationship (single, widow or divorced) are more likely to accept our offer than those who are (together or married). This is particularly valuable if we want to target customers later on.
pd.crosstab(
index=data['Education'], columns=data['Response'],
normalize='columns'
).round(2)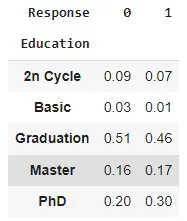
Doing the same exercise with the Education variable, we see that higher education levels (Master and PhD) make people more likely to accept an offer.
Outliers
It is not the case here, but sometimes there are outliers related exclusively to the bivariate relationships. For instance, if you have a very strong positive correlation between Income and MntWines, and then one customer is very poor but still spends a lot of money in wines, they can be considered in this case. This type of outlier does not need to be excluded, but it might be worth it looking at them more closely to understand why they behave like that.
Multivariate data analysis
Finally, there are some interesting analyses we can do involving more than two variables at once.
Factors
First of them is factor analysis, a statistical technique used to identify underlying relationships between variables in a dataset. It is often used in social sciences and psychology to identify underlying factors or latent variables that are associated with a set of observed variables.
In factor analysis, the observed variables are modeled as a linear combination of the underlying factors, plus some error. The goal of the analysis is to identify the underlying factors that best explain the observed variables, and to estimate the factor loadings, which are the correlations between the observed variables and the underlying factors.
You can read more about it here.
There are a few ways we can visualize those factors and their relationship to the original variables, but I chose a scatter plot because I thought it looked better:
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import FactorAnalysis
data_subset = data[continuous_vars].dropna()
data_subset = data_subset[(np.abs(stats.zscore(data_subset)) < 2).all(axis=1)]
# Scaling data
X = data_subset[continuous_vars].dropna().to_numpy()
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Create a FactorAnalysis object and fit it to our data
fa = FactorAnalysis(n_components=2)
fa.fit(X_scaled)
# DataFrame for visualization
fa_components = pd.DataFrame(fa.components_.T)
fa_components.index=continuous_vars
# Scatter plot
ax = fa_components.plot.scatter(x=0, y=1, alpha=0.5)
# Annotate each data point
for i, txt in enumerate(fa_components.index):
ax.annotate(txt, (fa_components[0].iat[i]+0.05, fa_components[1].iat[i]))
plt.show()
This is how we can interpret that plot:
- The X axis represents the first factor, which is the single combination of all features that accounts for the most variance in the original data
- The Y axis represents the second factor, which is the single combination of all features that accounts for the second most variance in the original data
- Each dot represents a feature, and its position shows the correlation of that feature with the factors
- The first factor seems to summarize the Mnt… variables
- The second factor seems to summarize the variables related to number of purchases
Another interesting way to look at it is by customer, instead of variable:
# DataFrame for visualization
fa_transformed = pd.DataFrame(fa.transform(X_scaled))
# Scatter plot
ax = fa_transformed.plot.scatter(x=0, y=1, alpha=0.5)
plt.show()
There seem to be two different groups of customers: one for which the two first factors are positively related, and another one for which they are negatively correlated.
My intuition says it might have something to do with income, so I add Income to that plot as a color:
# DataFrame for visualization
fa_transformed = pd.DataFrame(fa.transform(X_scaled))
# Scatter plot
ax = fa_transformed.plot.scatter(
x=0, y=1, c=data_subset['Income'],
colormap='viridis'
)
plt.legend()
plt.show()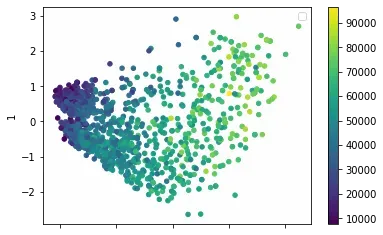
The lower income group seems to be the group with the negative correlation, but it’s hard to tell (it could just be due to the negative correlation between Income and the first factor).
Next steps
During this analysis, we have raised many questions, so now it’s time to define the possible next steps to answer them:
- Create "% of spending per category" feature
- Create "max of AcceptedCmp" feature
- Create "log" features to account for non-linear relationships
- Test which value works best to fill missing Income values: median or regression?
- Decide whether to delete outliers or not. I probably wouldn’t, since the only extreme outlier is the one really high value for Income, which is still possible in theory
- Clean Marital_Status variable (replace "YOLO", "Absurd", and "Alone" with "Single")
- Check if it makes sense to have that many PhDs in our sample: is it a store near a research lab?
Conclusion
My goal with this example was to provide you with a structured framework for EDA: from univariate analysis to multivariate analysis, covering the most common types of variable.
This is the basic framework I use for my analyses, while always keeping in mind the end goal of the analysis and the next steps each conclusion entails.
If you have any insights on this framework or if you think an important step is missing, please let me know in the comments!
The full code is available here, if you want to explore the whole thing.
Feel free to reach out to me if you would like to discuss further, it would be a pleasure (honestly):
Level Up Coding
Thanks for being a part of our community! Before you go:
- Clap for the story and follow the author
- View more content in the Level Up Coding publication
- Free coding interview course ⇒ View Course
- Follow us: Twitter | LinkedIn | Newsletter


Enjoy the read? Reward the writer.Beta
Your tip will go to Arthur Mello through a third-party platform of their choice, letting them know you appreciate their story.
Sign up for Top Stories
By Level Up Coding
A monthly summary of the best stories shared in Level Up Coding Take a look.
By signing up, you will create a Medium account if you don’t already have one. Review our Privacy Policy for more information about our privacy practices.

